Pojęcie fabryki AI spopularyzowała Nvidia. Firma opisuje je jako nowy typ centrum danych, które nie tylko przechowuje dane, lecz „produkuje inteligencję w skali przemysłowej”: od przetwarzania danych, przez trenowanie i dostrajanie modeli, aż po ich masowe uruchamianie w aplikacjach. Takie obiekty są projektowane od początku pod GPU, bardzo gęste zasilanie i chłodzenie oraz kompletny stos oprogramowania, a nie jako zwykła serwerownia z „doklejonymi” akceleratorami.
Inżynierowie Nvidii mówią wręcz o „AI‑scale data centers”, których skala ma sięgać setek megawatów, a nawet wielu gigawatów mocy. Na konferencji Data Center World 2025 firma pokazała wizję takich ośrodków jako głównego trendu w kolejnej dekadzie, z naciskiem na bardzo gęste zasilanie, chłodzenie cieczą i bliską integrację z siecią energetyczną.
W praktyce fabryka AI to więc wielki kampus danych, zaprojektowany do trenowania i obsługi modeli klasy GPT, a nie zwykły „cloud region”. I to właśnie takie obiekty są teraz planowane w największej skali.
Spis treści

Projekt Stargate: gigantyczna infrastruktura OpenAI
Stargate w USA
Największy dziś ogłoszony plan to projekt Stargate, projekt ogłoszony przez firmę Open AI. Głównymi partnerami nowej firmy Stargate jest Open AI i SoftBank. Firma zapowiedziała, że w ciągu czterech lat chce zainwestować około 500 miliardów dolarów w infrastrukturę AI w Stanach Zjednoczonych, z czego około 100 miliardów ma być wydane od razu na pierwszą falę centrów danych i powiązanych inwestycji energetycznych.

Równolegle przecieki i analizy branżowe opisują sam „rdzeń” Stargate jako pojedynczy kampus superkomputera i centrum danych za około 100 miliardów dolarów, który miałby ruszyć około 2028 roku i ostatecznie wymagać nawet do 5 gigawatów mocy elektrycznej. To poziom porównywalny z dużą elektrownią jądrową.
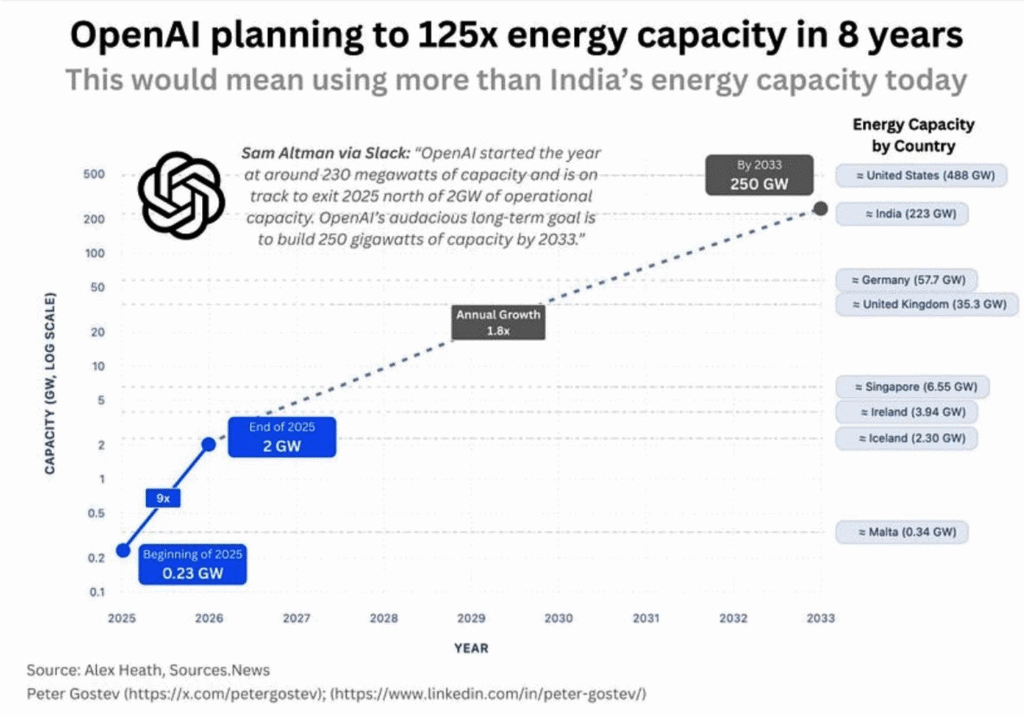
Projekt nie ogranicza się do jednego budynku. Chodzi o sieć ogromnych centrów danych, linie wysokiego napięcia, zaawansowane chłodzenie oraz warstwę oprogramowania, która ma zapewnić OpenAI i jej partnerom stały dopływ mocy obliczeniowej do trenowania kolejnych generacji modeli.

Umowy z Oracle i innymi dostawcami chmury
Częścią strategii Stargate jest także „wypożyczanie” gotowej infrastruktury od partnerów. Financial Times opisuje umowę OpenAI z Oracle na około 30 miliardów dolarów, w ramach której OpenAI ma dostęp do około 4,5 gigawata mocy obliczeniowej w centrach danych Oracle. Operator zapowiada przy tym rozbudowę istniejącego kampusu o mocy 1,2 gigawata w Abilene w Teksasie oraz budowę kolejnych ośrodków w USA, finansowanych m.in. poprzez rekordowe zakupy procesorów Nvidii.
To oznacza, że część „fabryk AI” będzie w praktyce hostowana w istniejącej infrastrukturze chmurowej, ale projektowanej od początku pod bardzo gęste, GPU‑owe obciążenia.

Stargate UAE: gigawatowa fabryka AI w Abu Zabi
Drugim filarem jest Stargate UAE w Abu Zabi. OpenAI ogłosiło, że we współpracy z G42, Oracle, Nvidią, Cisco i SoftBankiem zbuduje tam klaster obliczeniowy o docelowej mocy 1 gigawata, z pierwszą fazą 200 megawatów planowaną do uruchomienia w 2026 roku.
Według komunikatu OpenAI ma to być pierwsze wdrożenie globalnej platformy Stargate poza USA i jednocześnie jedno z największych centrów AI na świecie. Klaster ma obsługiwać zapotrzebowanie na moc obliczeniową w promieniu około dwóch tysięcy mil oraz stać się centralnym elementem nowego kampusu AI w Zjednoczonych Emiratach Arabskich.
Dla ZEA to sposób, by stać się regionalnym hubem AI. Dla OpenAI i partnerów jest to kolejny „węzeł fabryki AI” w sieci połączonych gigawatowych centrów danych.
Jak to wygląda w Polsce?
Helios w Krakowie
Polska infrastruktura obliczeniowa jest istotną częścią fabryk AI. Jednym z najbardziej wyrazistych przykładów takiego podejścia jest superkomputer Helios działający w Cyfronecie AGH. To maszyna zaprojektowana do wykonywania ogromnych obliczeń potrzebnych w projektach naukowych, przemysłowych i komercyjnych. Jego moc liczona w petaflopsach umożliwia trenowanie modeli językowych, analizę genomu, obróbkę obrazów medycznych oraz symulacje wykorzystywane w fizyce i inżynierii. Helios był także użyty przy tworzeniu polskiego modelu językowego Bielik, co podkreśla jego znaczenie dla krajowego ekosystemu AI.
Serwerownia Cyfronetu jako fundament dużych obciążeń obliczeniowych
Helios pracuje w ośrodku wyposażonym w wielotorowe zasilanie, zaawansowane systemy chłodzenia oraz wysoką gęstość energetyczną. Takie środowisko pozwala utrzymywać klastery GPU działające bez przerwy i obsługiwać wymagające obliczenia. Cyfronet od wielu lat rozwija polską infrastrukturę HPC, tworząc miejsce, w którym naukowcy i firmy mogą korzystać z mocy obliczeniowej niedostępnej w zwykłych serwerowniach.
Atman i pozostałe firmy budujące polskie zaplecze AI
W Warszawie znaczącą rolę odgrywa infrastruktura Atmana. Obiekty WAW1 i WAW2 należą do największych w kraju i zapewniają stabilne środowisko do utrzymywania serwerów GPU, co jest potrzebne przy rozwoju systemów rekomendacyjnych, analityki oraz modeli generatywnych. Wiele firm z branż regulowanych korzysta z ich usług, ponieważ wymagają, aby dane pozostały na terenie Polski.
Beyond.pl jako najbardziej odporne centrum danych w regionie
Poznański obiekt Data Center 2 firmy Beyond.pl to jedyne centrum Rated 4 w Europie Środkowej. Zaprojektowano je tak, aby mogło działać nawet przy awarii głównej części infrastruktury. Wysoki poziom redundancji i niezawodności sprawia, że centrum nadaje się do długotrwałych procesów trenowania modeli AI. Rozwijany przez firmę kampus w Piotrkowie Trybunalskim ma osiągnąć dziesiątki megawatów mocy, co czyni go obiektem przystosowanym do epoki generatywnej sztucznej inteligencji.
Globalni operatorzy i polskie regiony chmurowe
Region Google Cloud Poland oraz Azure Poland Central stworzyły warunki do obsługi projektów, które wymagają lokalnego przetwarzania danych. Dzięki temu firmy rozwijające sztuczną inteligencję mogą korzystać z globalnych usług obliczeniowych bez opuszczania polskiej jurysdykcji. Equinix, poprzez swoje kampusy WA1, WA2 i nowy WA3 pod Warszawą, łączy lokalne serwerownie z międzynarodowymi sieciami, co umożliwia budowanie hybrydowych architektur wykorzystywanych w systemach AI.
Ekosystem wspierający polskie firmy technologiczne
Rozwój infrastruktury centrów danych sprawia, że firmy takie jak Synerise, Infermedica, Nethone, Eleven Labs, Surveily, Nomagic oraz SentiOne mogą rozwijać narzędzia konkurencyjne wobec rozwiązań globalnych. Te przedsiębiorstwa potrzebują dużych zasobów GPU, niskich opóźnień i bezpiecznej architektury obliczeniowej. Polski rynek oferuje im środowisko zdolne do obsługi takich projektów, co bezpośrednio wpływa na tempo tworzenia nowych modeli i eksperymentów.
Polska sieć centrów danych jako fundament transformacji cyfrowej
Rosnący popyt na moc obliczeniową powoduje, że kolejne inwestycje powstają w okolicach Warszawy, Poznania i Krakowa. Obiekty te tworzą kręgosłup polskiej gospodarki cyfrowej. Od superkomputera Helios, przez Atmana i Beyond.pl, aż po globalnych dostawców chmurowych rozwija się sieć obiektów, które zamieniają dane i energię w realne systemy sztucznej inteligencji. Dzięki temu Polska staje się jednym z najważniejszych punktów obliczeń w Europie Środkowej i kluczowym miejscem dla rozwoju nowoczesnych technologii.
Gigawatowe „blueprinty” Nvidii i 10 GW centrów dla OpenAI
Nvidia nie tylko sprzedaje procesory, ale też proponuje gotowy „szablon” fabryk AI. Na konferencji GTC 2025 ogłoszono projekt Omniverse DSX, czyli referencyjny projekt centrów danych o mocy od stu megawatów do kilku gigawatów. W materiałach technicznych opisano je wprost jako „AI factories”, których zużycie energii jest porównywalne z elektrownią jądrową, a całość ma być projektowana i optymalizowana w formie cyfrowego bliźniaka przed faktyczną budową.
Ten sam blueprint ma leżeć u podstaw między innymi ośrodka o mocy około 2 gigawatów w stanie Georgia oraz kampusu Stargate w Teksasie, szacowanego na około 1,2 gigawata.
Osobno Associated Press informuje, że Nvidia zobowiązała się zainwestować około 100 miliardów dolarów w OpenAI w formie sprzętu i infrastruktury, współfinansując budowę co najmniej 10 gigawatów centrów danych AI. Pierwszy gigawat systemów Nvidii ma zostać uruchomiony w drugiej połowie 2026 roku.
W praktyce oznacza to serię co najmniej kilku bardzo dużych kampusów AI, rozrzuconych po USA i innych regionach, które będą działały jako jedna, logicznie połączona „fabryka inteligencji”.
Chipowe zaplecze fabryk AI: TSMC, Samsung, Rapidus, Intel
Same centra danych nie wystarczą, potrzebne są jeszcze czipy. Dlatego równolegle powstają wielkie fabryki półprzewodników, projektowane wprost z myślą o procesorach dla AI.
- TSMC ogłosiło, że łączna wartość inwestycji w USA wzrośnie do około 165 miliardów dolarów. Obejmuje to dodatkowe 100 miliardów na trzy nowe fabry w Arizonie, dwa zakłady zaawansowanego pakowania oraz duże centrum badawczo‑rozwojowe. Władze stanowe i lokalne opisują ten pakiet jako największą zagraniczną inwestycję w historii USA, a TSMC wprost łączy go z rosnącym popytem na czipy dla AI i centrów danych.
- Samsung zapowiedział z kolei inwestycje rzędu 450 bilionów wonów, czyli ponad 300 miliardów dolarów, w ciągu najbliższych pięciu lat; mają one objąć rozwój AI, produkcję półprzewodników oraz infrastrukturę centrów danych. To uzupełnia wcześniejszą deklarację, że do 2042 roku firma zainwestuje około 230 miliardów dolarów w budowę największego na świecie klastra produkcji czipów w Korei Południowej.
- W Japonii pod marką Rapidus powstaje nowa fabryka układów w technologii 2 nm. Rząd japoński i prywatni inwestorzy przeznaczyli na projekt kilka miliardów dolarów; celem jest rozpoczęcie masowej produkcji w 2027 roku w fabryce na Hokkaido, z myślą między innymi o czipach dla AI i zastosowań wysokowydajnych.
- Intel z kolei planuje duże fabry w USA i Europie, choć część z nich została ostatnio opóźniona. Przykładowo projekt „Ohio One” o docelowej wartości około 100 miliardów dolarów został przesunięty; pierwsza fabryka ma ruszyć dopiero około 2030 roku, a kolejne etapy później.
Te inwestycje w czipy są de facto drugim poziomem „fabryk AI”: bez nich nie ma czym fizycznie wypełnić szaf w centrach danych.
Jak bardzo ta infrastruktura ma urosnąć do 2030 roku
Różne analizy próbują policzyć, jaka będzie skala całej infrastruktury AI w nadchodzącej dekadzie.
Goldman Sachs Research szacuje, że globalne zużycie energii przez centra danych wynosi dziś około 55 gigawatów, a łączna moc zainstalowana to około 59 gigawatów. Do 2030 roku ma to urosnąć do około 122 gigawatów mocy centrów danych, przy czym udział dużych operatorów chmurowych i kolokacyjnych ma wzrosnąć z około 60 do 70 procent. Według tych samych szacunków do końca dekady zapotrzebowanie na energię ze strony centrów danych może wzrosnąć nawet o 165 procent w porównaniu z 2023 rokiem, a udział obciążeń AI w miksie mocy ma wzrosnąć z około 14 do blisko 27 procent w 2027 roku.
McKinsey prognozuje z kolei, że popyt na moc centrów danych może rosnąć o 19 do 22 procent rocznie w latach 2023–2030, co dałoby w 2030 roku zapotrzebowanie na poziomie 171 do 219 gigawatów, a w scenariuszu bardziej agresywnym nawet blisko 300 gigawatów. Dla porównania obecne zapotrzebowanie to około 60 gigawatów.
Międzynarodowa Agencja Energetyczna i niezależne analizy ostrzegają, że energia zużywana przez centra danych obsługujące AI może do 2030 roku co najmniej się podwoić, a same wyspecjalizowane „AI‑datacenters” nawet czterokrotnie zwiększyć zapotrzebowanie na energię, co sprawi, że w USA ich zużycie prądu może dogonić lub prześcignąć tradycyjne gałęzie przemysłu energochłonnego, takie jak stal i cement. Jednocześnie około 20 procent planowanych projektów centrów danych już teraz mierzy się z opóźnieniami z powodu ograniczeń sieci i infrastruktury energetycznej.
Raporty CBRE i JLL wskazują, że praktycznie cały rynek inwestycyjny „rzuca się” na ten sektor. W ankiecie CBRE aż około 95 procent dużych inwestorów deklaruje zamiar zwiększenia ekspozycji na centra danych, a głównym motorem popytu są właśnie obliczenia AI. JLL ocenia, że globalna moc centrów danych powinna rosnąć w tempie około 15 procent rocznie w najbliższych latach, choć i tak może to być za mało, aby nadążyć za zapotrzebowaniem generowanym przez sztuczną inteligencję.
W skrócie: to, co jeszcze niedawno było kilkoma „hiperskalowymi” regionami chmurowymi, zamienia się w globalny program budowy przemysłowej infrastruktury obliczeniowej, z budżetami liczonymi w setkach miliardów dolarów i zapotrzebowaniem na energię porównywalnym z całymi sektorami gospodarki.
Podsumowanie
- Wieloletni program Stargate OpenAI w USA, sięgający około 500 miliardów dolarów inwestycji w infrastrukturę AI, z pojedynczym kampusem superkomputera rzędu 100 miliardów dolarów i zapotrzebowaniem do 5 gigawatów.
- Klaster Stargate UAE w Abu Zabi o docelowej mocy 1 gigawata, z pierwszą fazą 200 megawatów w 2026 roku, jako jedno z największych centrów AI na świecie.
- Sieć gigawatowych centrów danych zaprojektowanych według blueprintów Nvidii, w tym co najmniej 10 gigawatów infrastruktury dla OpenAI, finansowanych m.in. inwestycją Nvidii na około 100 miliardów dolarów.
- Mega‑inwestycje w fabryki czipów, w tym 165 miliardów dolarów TSMC w USA, setki miliardów dolarów Samsunga w Korei i globalne projekty takie jak Rapidus w Japonii czy opóźniony, ale nadal ogromny kompleks Intela w Ohio.
Do tego dochodzi fala dziesiątek „mniejszych” kampusów po kilkadziesiąt megawatów każdy, które razem mają podwoić, a być może nawet potroić globalną moc centrów danych do końca dekady.


